
Adapting Data Models in Python
One interesting problem that we face often when integrating systems, be it from different companies or within the same organisation, is transforming data from the model used in one system to the model used in the other system.
Faced with the challenge of having to do this quite often, I designed py-transmuter, a Python library that simplifies the process of transforming data objects by allowing the user to simply create a static definition of how the fields of one model map to the other and automating the transformation itself.
Why not just use py-automapper?
There is a great Python library out there called py-automapper that makes mapping between models extremely easy; if what you are doing is simply moving data from one data model to the next, this should be your go-to library. The limitation of this great library is that it doesn’t easily let you transform the data you’re mapping or aggregate it like py-transmuter does. So let’s go ahead and see why using py-transmuter is a good idea!
The Problem
It is not unlikely that at some point in our development career we’ll come across the task of fetching data from some external party and store it in our systems. It is also not unlikely that, when doing this, we’ll need to adapt the information somehow because their data model is different to our data model.
This problem can take multiple shapes, three of them are:
- We need to map objects one to one from the source data model to the target data model.
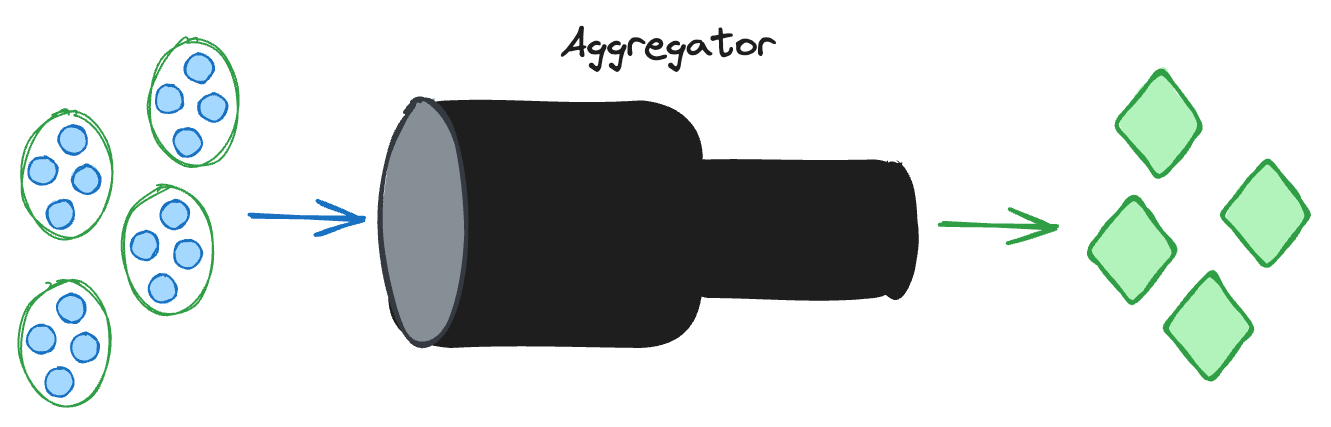
- We need to aggregate objects, transforming many of the source data model to a single object of the target data model.
- We need to de-aggregate (or interpolate) objects, transforming one object of the source data model to many of the target data model. We will not be discussing this problem here.
What py-transmuter proposes for these problems is introducing a Mapper for the first one and an Aggregator for the second one. These would look like:

A concrete example
This sounds all very nice, but without a concrete example it might be difficult to fully grasp what kind of problem exactly we want to solve exactly.
Imagine your organisation uses weather data as one of the main inputs for calculating the output of ✨ an amazing product ✨. Imagine also that this data is stored in a very specific way: a time series where each entry represents 15 minute intervals with a temperature value in Celsius.
Now the trick is that this data is ingested from different providers, and each provider has their own way of storing their data; let’s look at some of them:
- MericaWeather: They have 15 minute intervals (in
ESTtimezone) and their temperature measures are in Fahrenheit. - SunWatch: They have 1 minute intervals (in
UTCtimezone) that have measures in Celsius.
More specifically, each reading in their responses looks like:
@dataclass
class MericaWeatherReading:
quarter: datetime # 15 minute intervals in EST
temperature: Decimal # Fahrenheit values
@dataclass
class SunWatchReading:
timestamp: datetime # 1 minute intervals in UTC
measurement: Decimal # Celsius values
Of course, normally you’d get a bunch of readings at a time, so we can assume that their actual API responses are something like:
class MericaWeatherResponse:
readings: list[MericaWeatherReading]
class SunWatchResponse:
readings: list[SunWatchReading]
To complete the example we need to know how our model looks, which could be something like:
@dataclass
class IntervalTemperature:
interval_start: datetime # 15 minute intervals in UTC
value: Decimal # Celsius values
Now that we have our problem definition clear, we can proceed to what py-transmuter can do for you.
The Solution
What we need to do should be very clear by now:
For MericaWeather we need to transform each entry’s quarter to UTC and assign it to interval_start and each temperature to Celsius and assign it to value. We want something like this:
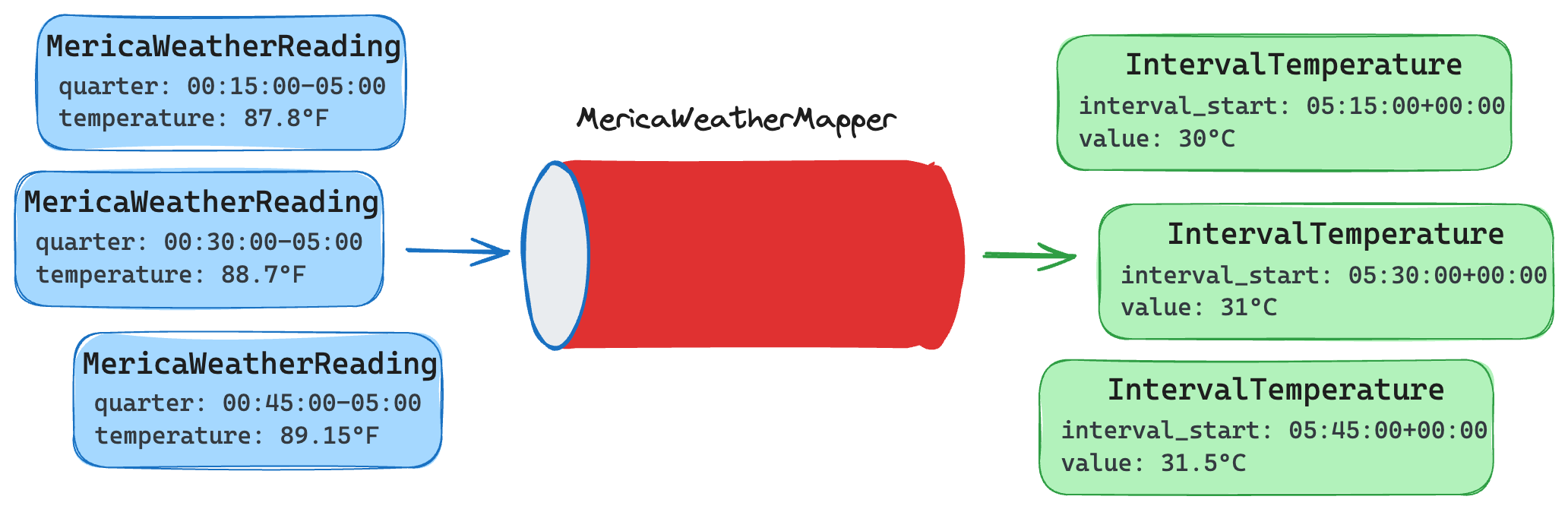
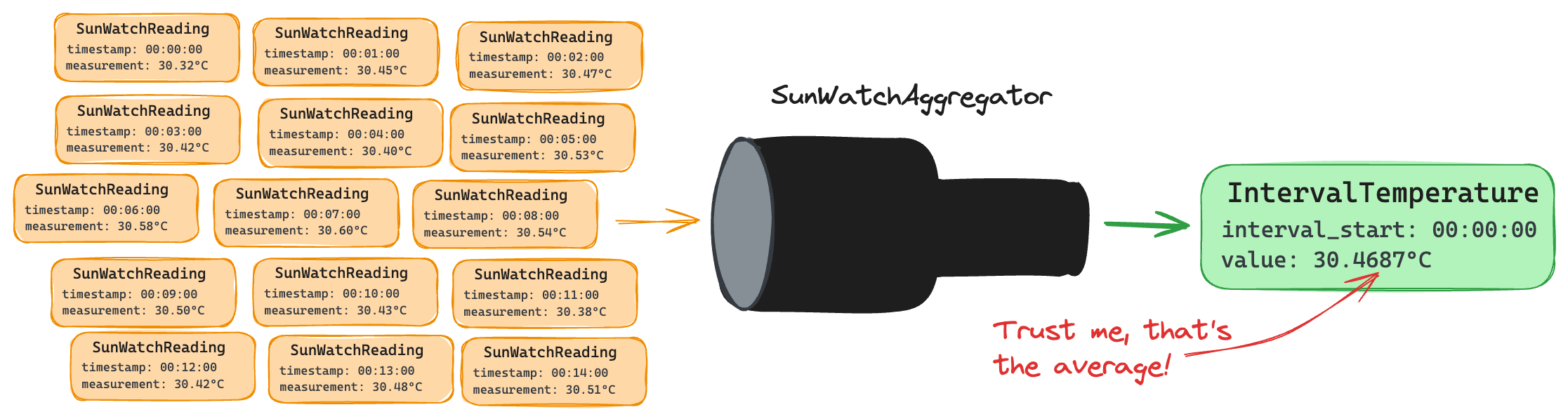
For SunWatch we need to aggregate every 15 entries and average the values (this is an arbitrary decision); so we’d grab the first timestamp of each 15 entry group and set it as our interval_start and we’d set our value as the average of each of the group’s entries measurement. We want something like this:
Each of these problems can be represented as two different things: the first one is simply mapping one entity from one model to another and the second one requires certain aggregations aside from the mapping. Let’s look at each one individually.
Mapping
The great thing about py-transmuter is that all you need to do is define how models map to each other and what functions we need to transform specific fields. A Mapper for the transformation MericaWeatherReading -> IntervalTemperature would look like:
import pytz
from py_transmuter.models.mapper import ModelMapper
def to_utc(est_timestamp: datetime) -> datetime:
return est_timestamp.astimezone(pytz.UTC)
def fahrenheit_to_celsius(fahrenheit: Decimal) -> Decimal:
return (farenheit - 32) × 5/9
class MericaWeatherMapper(ModelMapper[IntervalTemperature, MericaWeatherReading]):
mappings = {
"interval_start": ("quarter", to_utc),
"value": ("temperature", fahrenheit_to_celsius),
}
Now that we have our mapper defined, getting our IntervalTemperature objects is as simple as:
response = MericaWeatherResponse(readings=...)
mapped_objects = MericaWeatherMapper().map_list(response.readings)
And that’s it!
Aggregating
For aggregating multiple instances of the “source model” into our “target model”, we need to do something similar; let’s get right into it:
from statistics import mean
from py_transmuter.models.aggregator import ModelAggregator
first = lambda iterable: iterable[0]
def closest_fifteenth_minute(reading: SunWatchReading) -> datetime:
"""This method always returns the start of a 15 minute interval.
If the reading has timestamp 14:13:00, this will return 14:00:00."""
timestamp = reading.timestamp
closest_15 = (timestamp.minute // 15) * 15
minute_difference = closest_15 - timestamp.minute
new_dt = timestamp + timedelta(minutes=minute_difference)
return new_dt.replace(second=0, microsecond=0)
class SunWatchAggregator(ModelAggregator[IntervalTemperature, SunWatchReading]):
group_by = (closest_fifteenth_minute,)
sort_by = ("timestamp",)
aggregations = {
"interval_start": ("timestamp", first),
"value": ("measurement", mean),
}
As with the mapper, getting our IntervalTemperature objects now is as simple as doing:
response = SunWatchResponse(readings=...)
aggregated_objects = SunWatchAggregator().aggregate(response.readings)
Now this might look a little bit more complex, but what’s important is that we’re only focusing on the aggregation logic, without caring about object instantiation. Let’s look a little bit more in detail what’s happening here.
When we tell our Aggregator to sort_by the timestamp field, we ensure that all the provided objects (in our case the response.readings) will be processed ascending by the indicated field. This allows us to define all our aggregation functions knowing that the received records will be in whichever order we indicated; in this case, ascending by timestamp.
By telling the Aggregator that we want to group_by using the closest_fifteenth_minute function, we ensure that all the entries that are within the same 15 minute interval will be aggregated together; this is, any reading between XX:00 and XX:14 will be together, as well as any reading between XX:15 and XX:29 and so on.
Finally, knowing that we’re aggregating readings within the same fifteen minute interval that are also sorted by their timestamp, we can simply create our reading objects by setting the interval_start as the first timestamp of the group (which will always be the beginning of the interval) and the value as the mean of all the measurements in the group.
When static defitions simply don’t cut it
In our example above we were always working with UTC timezones in our “internal” service. Most times, things like these are not really static and vary depending on something from the context; for example, the geographical area for which we’re forecasting weather.
Imagine now that, instead of always using UTC in our system, we want to map the response of MericaWeather using a timezone that we only know during runtime; for example, the timezone of a given European country. Since both the Mapper and the Aggregator in py-transmuter can “inspect themselves”, this is very easily achieved by accessing the (optional) context attribute that these classes have; look:
from py_transmuter.models.mapper import ModelMapper
class MericaWeatherMapper(ModelMapper[IntervalTemperature, MericaWeatherReading]):
def to_local_timezone(self, est_timestamp: datetime) -> datetime:
return est_timestamp.astimezone(self.context["timezone"])
@staticmethod
def fahrenheit_to_celsius(fahrenheit: Decimal) -> Decimal:
return (farenheit - 32) × 5/9
mappings = {
"interval_start": ("quarter", to_local_timezone),
"value": ("temperature", fahrenheit_to_celsius),
}
This new Mapper now accesses it’s context and extracts the timezone argument, which assumes will be present during runtime. Of course, when we instantiate it, we need to do:
country = Country(timezone='Europe/Amsterdam')
# ...
mapper = MericaWeatherMapper(context={"timezone": country.timezone})
# ...
response = MericaWeatherResponse(readings=...)
mapped_objects = mapper.map_list(response.readings)
The curious reader would wonder what’s the extent of this feature. To put it simply, anything that belongs to the class can be accessed. You can define a @staticmethod within the class and add it in the mappings or aggregations dictionary, you can define a @classmethod that access a class variable and, as we saw in the example, you can use instance methods as well.
The curious (and attentive) reader would also wonder if setting class specific instance attributes instead of accessing the context is possible. The answer is yes:
class MyMapper(ModelMapper[SourceModel, TargetModel]):
instance_var: Any
class_var: ClassVar[Any]
def __init__(self, instance_var: Any, *args, **kwargs):
self.instance_var = instance_var
super().__init__(*args, **kwargs)
def instance_method(self, value: Any) -> Any:
# This works!
return self.instance_var
@classmethod
def class_method(cls, value: Any) -> Any:
# This also works!
return cls.class_var
The Implementation Details
In order to avoid making this blog post too long, I will save you the details of the implementation. The good thing about open source is that you can go ahead and look at it yourself from top to bottom, upside down and from the sides in the library’s repository.
Please go ahead and do it! I would definitely appreciate to have as many eyes as possible and receive as many critics and suggestions as I can handle.
Conclusion
Hey! You made it to the end! Thanks for sticking with me all the way!
If you were hunting for a solution to your problem, I hope you found it here. If not, maybe you stumbled upon something that sparks some inspiration. Or at the very least, I hope this read has jiggled some synapses and sparked some killer ideas for later!
Everything we discussed here is open source and open to suggestions and improvements. If you have any ideas, concerns or questions, don’t hesitate to reach out, open a Pull Request or even create an Issue in the library’s repository.